
QQ图片20190820093209.png (386.56 KB, 下载次数: 0)
46,225 mm2 silicon
1.2 trillion transistors
400,000 AI optimized cores
18 Gigabytes of On-chip Memory
9 PByte/s memory bandwidth
100 Pbit/s fabric bandwidth
TSMC 16nm process
21.5cm*21.5cm
有谁不服的?
anandtech的链接,细节可以过去看
https://www.anandtech.com/show/14758/hot-chips-31-live-blogs-cerebras-wafer-scale-deep-learning
评论
这名字吓我一跳,怎么和zen3这么像,仔细一看才知道不是
评论
请问3匹空调柜机能压的住么
评论
一颗芯片用一片晶圆系列,这个得多钱啊
评论
据多家外媒 8 月 19 日报道,美国 AI 芯片初创公司 Cerebras Systems 推出了有史以来最大的芯片,这款名为“The Cerebras Wafer Scale Engine”的芯片(下文称 WSE)有 1.2 万亿个晶体管。
在芯片历史上,1971 年,英特尔的第一个 4004 处理器只有 2300 个晶体管,而最近的一个高级微设备处理器也只有 320 亿个晶体管。三星也曾制造过一款拥有 2 万亿个晶体管的闪存芯片( eUFS 芯片),但是不适用于 AI 计算。
WSE,这个创纪录的最大芯片,它为 AI 计算而生。

(来源:Cerebras Systems)
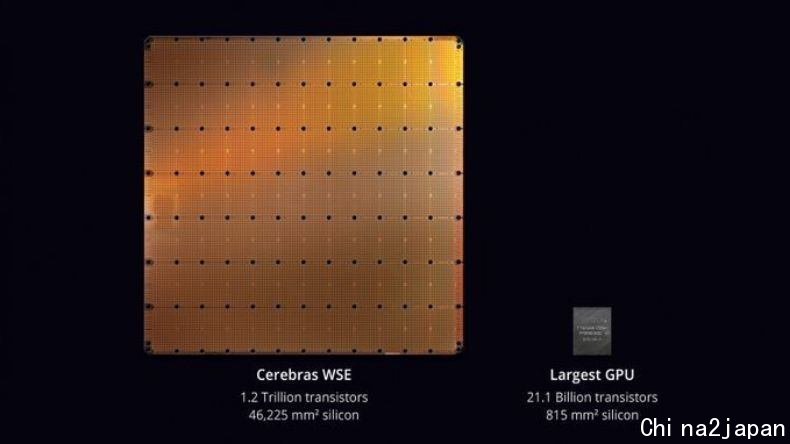
数据显示,这个 42,225 平方毫米的芯片,有着 400,000 个核,这些核心通过一个细粒度、全硬件的片内网状连接的通信网络连接在一起,提供每秒 100 PB 的总带宽。更多的核心、更多的本地内存和低延迟的高带宽结构,创建了加速人工智能工作的最佳架构。WSE 比最大的 GPU 还要大 56.7 倍,拥有 18 GB 的 on-chip sram。
事实上,现在的大多数芯片是在 12 英寸硅片基础上制作的多芯片集成。但 Cerebras Systems 公司的这款芯片是晶体管在单晶硅圆片上制作互相连接的独立芯片。其互相连接的设计,可以让所有的晶体管都能如一个整体一般高速运转。
(来源:Cerebras Systems)
通俗地解释,这款产品完全就是计算机中的学霸,比计算能力和存储带宽,不好意思,人家的级别还是新词汇——拍字节(Petabytes,1PB=1024TB=10^6GB=2^50bit),速度大约是如今英伟达公司最大的图形处理器(GPU,浮点运算能力很强,常用于 AI 相关研究)的 3000 倍,存储带宽则是 1000 倍。
如此强大的能力来源于其片上的 1.2 万亿个晶体管,要知道 1971 年 Intel 的 4004 处理器才有 2300 个晶体管,按照摩尔定律来推算:“每 18 个月,芯片上晶体管数目翻倍”,到今年应该刚好 1 万亿个晶体管,多一个晶体管,能实现的计算能力就增加一分。其次,其芯片架构设计和芯片互联及通信方案也是十分超前的,使得 1.2 万亿个晶体管之间的协同十分同步,延迟达纳秒(nanosecond)级,运行时,这 1.2 万亿个晶体管就像一个晶体管一样同步。
(来源:推特)
在人工智能领域,芯片的大小非常重要。因为大型芯片处理信息的速度更快,产生答案的时间更短。减少观察的时间,或“训练时间”,可以让研究人员测试更多的想法、使用更多的数据,并解决新的问题。谷歌、Facebook、OpenAI、腾讯、百度,以及其他许多公司都认为,如今人工智能发展的根本局限在于,训练模型的时间太长。因此,减少训练时间将消除整个行业进步的一个主要瓶颈。
当然,芯片制造商通常不生产大型芯片也是有原因的。在单个晶圆片上,制造过程中通常会出现一些杂质。一点杂质就可以导致芯片故障,严重的甚至会击穿几个芯片。如果单个晶圆片上只制作一个芯片,那么它含有杂质的可能性是 100%,杂质肯定会使芯片失效。但是 Cerebras Systems 的芯片设计是留有裕量的,能够保证一个或者少量杂质不会使整个芯片失效。

图| Andrew Feldman(来源:Dean Takahashi)
Cerebras Systems 公司 CEO Feldman 在一份声明中说,“公司的 WSE 芯片专为人工智能而设计,包含基本的创新,解决了限制芯片尺寸几十年的技术挑战,如 十字交叉连接、良率、功率输出和封装。每一个架构决策都是为了优化人工智能工作的性能。其结果是,WSE 芯片在功耗和空间很小的情况下,根据工作负载提供了现有解决方案数百或数千倍的性能。”
这些性能的提高是通过加速神经网络训练的所有要素来实现的。神经网络是一个多级计算反馈回路。输入通过循环回路的速度越快,回路学习或“训练”的速度就越快。让输入更快地通过循环的方法是加快循环内的计算和通信的速度。
在通信架构上,由于在 WSE 上使用了中继处理器,集群通信的架构突破了传统通信技术中部分功率消耗而导致的带宽和延时的问题。通过使用二维阵列结构将 400,000 个基于 WSE 的处理器连接在一起,集群架构实现了低延时以及高带宽的特性,其总体带宽可以高达每秒 100 拍字节(1017 字节/每秒)。即使没有安装任何的额外软件,这样的集群结构也可以支持全局信息处理,并由相应的处理器对所接收到的信息进行处理。

(来源:Cerebras Systems)
对于这款产品,量产和散热可能会是其面临的主要挑战。但是,WSE 的问世,本身的亮点已经足够。
Linley Group 首席分析师 Linley Gwennap 在一份声明中表示:“Cerebras Systems 在晶圆级封装( wafer-scale package)的技术上取得了巨大进步,在一块硅片上实现的处理性能远远超出任何人的想象。为了实现这一壮举,该公司已经解决了困扰该行业数十年的一系列工程挑战,包括实现高速模对模通信、解决制造缺陷、封装如此大的芯片、提供高密度电源和冷却系统。Cerebras Systems 通过将不同学科的顶尖工程师聚集在一起,创造了新技术,并在短短几年内交付了一个产品,这是一个令人印象深刻的成就。”
Tirias Research 首席分析师兼创始人 Jim McGregor 在一份声明中表示:“到目前为止,重新配置的图形处理器满足了人工智能对计算能力的巨大需求。如今的解决方案将数百个这些重新配置的图形处理器连接在一起,还需要数月的时间安装,使用数百千瓦的电力,并要对人工智能软件进行广泛修改,甚至还要数月的时间来实现功能。与之相比,单片 WSE 芯片的绝对大小能够实现更多的计算、更高性能的内存和更大的带宽。通过晶圆级 (wafer-scale) 封装的集成技术,WSE 芯片避免了松散连接、慢内存、基于缓存、以图形为中心的处理器的芯片固有的传统性能限制。

(来源:Cerebras Systems)
Cerebras Systems 成立于 2016 年,自成立以来在业内相当神秘低调,专注于为数据中心进行训练提供芯片产品,曾被 CB Insights 评为“全球最值得期待的 100 家芯片公司”。资料显示,该公司曾于 2016 年完成 2500 万美元 A 轮融资,投资方为知名风投 Benchmark,后又获得多轮融资,截止 2017 年 9 月共获得 1.12 亿美元融资,估值 8.6 亿美元。
公司的创始团队背景实力也十分强劲。联合创始人及 CEO Andrew Feldman,曾经创立过芯片公司 SeaMicro,后被 AMD 在 2012 年以 3.34 亿美元收购。SeaMicro 被 AMD 收购后,原班人马大都进入 AMD 继续工作,所以当 Andrew Feldman 大旗一挥要继续创业时,很多老同事都选择了跟随,其他主要团队成员大都与创始人 Andrew Feldman 师出同门。
其中值得一提的人物是 Gary Lauterbach。在上世纪 90 年代 Sun 公司如日中天之时,Gary Lauterbach 就曾担任公司的高级芯片设计师,加之后来在 SeaMicro 主要从事低功耗服务器设计,可以说公司在创世之初就累积了一大批低功耗芯片设计的元老级人物,这对普通创业公司来说无疑可以说是赢在了起跑线上。
随后,在 2018 年,又有一位重量级人物加盟 Cerebras Systems,前 Intel 公司架构副总裁、数据中心首席技术官 Dhiraj Mallick 正式出任主管工程和商务的副总裁。此人在 Intel 任职期间,2018 年第二季度收入同比去年增长 10 亿美元,仅 2018 年上半年就将公司数据中心的收入提高到了 100 亿美元,是一位公认的技术与商业奇才。而他也正是 Andrew Feldman 在 SeaMicro 及 AMD 的老同事。现在,这家公司已有 194 名员工。
Cerebras Systems 未来要走的路还很长,但不难想象,AI 正带来一股计算机体系结构和芯片封装技术创新潮,可以期待,我们将见证更多更有趣甚至意想不到的 AI 芯片诞生。
评论
这良率能顶的住吗
评论
搞个大新闻先,当然是不可能量产的
评论
这玩意成功流片了。。?
评论
09:14PM EDT - Already in use? Yes
评论
CHH开箱贴已经有了--> https://www.chiphell.com/thread-2025860-1-1.html
评论
板凳这么大吗
评论
这链接不就是这个帖子么?被你骗了………
评论
这太牛逼了
评论
本质还是多芯片的晶圆级封装 只是这样做成本挺高的
评论
等你呢
评论
这是存算一体芯片。完全按照神经网络结构设计,最大程度减少缓存的交换。
评论
只要电压低。漏电率能控制在比较理想的情况下。
其实发热就不会太大。
评论
终于可以用来烤肉了
一点黄油 一块牛排 放上去滋滋作响 屋内瞬间香气四溢
评论
我本来以为又是忽悠,结果看了文章最后的作者简介,看起来还是很厉害?
评论
wdnmd……这良率还能看么……
评论
这种存算一体,和忆阻那种能力相比如何?
评论
新型暖手宝
评论
可以屏蔽不良的单元吧。。
评论
能量产么……咋封装啊……什么供电什么散热啊
评论
良率1%以下吧
评论
忆阻器是完全模仿人类神经元的,电信号经过的时候对忆阻单元进行改变,计算的过程是analog(后面还有个mimic,就不用模拟这个词了,会构成歧义)的。
这种存算一体芯片还是利用与非门,利用目前集成电路的技术mimic电信号的经过,等于是从新编排了缓存体系的传统芯片。
忆阻器其实不适合现在的神经网络计算方式,因为现行的流行的神经网络计算,本来就是用alu高度并行的计算过程,用高度并行的矩阵运算模拟神经元叠加的过程,自身就是mimic的,不是analog的。
说的有点绕,下面总结一下:
现行神经网络存算一体芯片 -> 矩阵计算 -> alu并行 -> 与非门
忆阻器芯片 -> 模拟电信号经过神经突触开合 -> 改变忆阻单元的电阻值 -> 测量
评论
看起来还是两个次元的啊 电路 电子 维修 我现在把定影部分拆出来了。想换下滚,因为卡纸。但是我发现灯管挡住了。拆不了。不会拆。论坛里的高手拆解过吗? 评论 认真看,认真瞧。果然有收 电路 电子 维修 求创维42c08RD电路图 评论 电视的图纸很少见 评论 电视的图纸很少见 评论 创维的图纸你要说 版号,不然无能为力 评论 板号5800-p42ALM-0050 168P-P42CLM-01
·中文新闻 阿曼达·斯蒂尔(Amanda Platell):哦,迈琳(Myleene),我对你的
·中文新闻 迪拜的秘密性交易 - 和加油的英国男人 - 暴露了:在一次特别调