声明:此文于2018年10月9日写成,拖到今天才发的原因很简单——发给 Nvidia 看了很久很久。。 文中没有就最近的花屏事件做说明——因为当时还没有遇到,之后笔者倒是遇到过一次,但是不是花屏,还是屏幕出现横杠条纹。全文每一个字均为原创,文中有一部分更正了部分媒体评测的错误——没有任何恶意和攻击的意思。请版主大佬帮忙指正格式或是其他注意事项,难得在 ChipHell 发帖,不熟悉,有错误一定接受批评。
立 Flag的事情国人是不喜欢做得,前怕狼后怕虎,中间还怕挤兑——但是这是对跟随者而言。对已经木秀于林的领先者来说,与其畏首畏尾,倒不如锐意向前,寻求自我突破。
NVIDIA 这次推出的新一代“Turning(图灵)”架构以及基于这个架构的 GeForce RTX 20xx 系列显卡,就是一次义无反顾的自我突破,颇有几分百尺竿头更进一步的宗师气象。
基于“Turning(图灵)”架构的 GeForce RTX
从“ Fermi(费米)”开始,NVIDIA 一直在用物理学家的名字命名自己的 GPU 核心,这之中我们看见了“开普勒”,“麦克斯韦”,“帕斯卡”和“伏打”,可以说每一代一出来就是秒天秒地,脚踏黄河两岸的那种身姿。 这之中只有“伏打”并没有大规模的推出消费级产品,只能在面向计算的 Tesla 产品线种看到 Tesla V100和稍低端一些的Tesla V60。非要说和消费级有关的那就是 Titan 系列的 Titan V 了——在RTX 2080Ti 诞生之前,绝对的卡皇。
“ Turning(图灵)”架构(下称TU102)伴随着2080Ti 推出其实挺意外的,一般来说因为新架构试水,加上产能和良品率的问题,新架构都是先出中高端的产品,等良品率上来以后才会出顶级的(如1080Ti 在1080之后才发)。RTX 2080Ti 生猛出世,难道说用的是老制程工艺?
非也!

[email protected] (96.09 KB, 下载次数: 0)
表1:官方公布的几个主要数据:12nm工艺带来了186亿晶体管的TU102核心——RTX 2080Ti 也因此拥有了4352个CUDA Core,重新架构的SM组也多达68个,如此多的晶体管却能维持功耗与GTX 1080Ti一样,足见工艺制程的优势
除却制程演进带来了更多的CUDA Core之外,TU102架构最耀眼的地方就是前所未有的加入了两种新的核心——Tensor Core(张量计算核心)以及 RT Core(光线追踪核心)。在RTX 2080Ti中,每一组SM都拥有8个Tensor Core,使得整个GPU拥有多达544个Tensor Cores,直接赋予了RTX 2080Ti近 114 Tensor FLOPS的计算力——后面笔者会单说这个计算力的用途。而RT Core则使得RTX 2080Ti 可以每秒做78万亿次(78 Trillion)光线追踪的操作(RTX-OPS)。
[email protected] (87.37 KB, 下载次数: 0)
 表2:可以看出TU102架构增加的晶体管里,有相当一部分被用做了Tensor Core和RT Core,而这在前一代的GTX 1080Ti中是什么都没有的——1080Ti纯用CUDA Core来做类似的计算
表2:可以看出TU102架构增加的晶体管里,有相当一部分被用做了Tensor Core和RT Core,而这在前一代的GTX 1080Ti中是什么都没有的——1080Ti纯用CUDA Core来做类似的计算
image001.jpg (99.41 KB, 下载次数: 0)
Tensor Core 和 RT Core 将成为显卡的基石NVIDIA这么做的理由很简单,它将自身的CUDA Core看做是通用处理器,而非显卡,那么对于通用计算来说,繁重的光线追踪创造做(RTX-OPS)和用于深度学习推演的张量计算(Tensor FLOPS)当然需要卸载(Offload),来提升效率。
举个例子,当年GPU出现之前,CPU承担了图形渲染和输出的操作——我们这里说的是x86指令集的CISC架构CPU,它的好处是通用,非常易于编程。坏处是,指令集复杂,指令的执行流水线很长(发展到奔腾4的时候已经令人发指,之后的酷睿直到今天都不敢再搞这么长的流水线了)。因此黄仁勋在1999年推出第一个GPU的时候,就明确了让CPU去做杂事,GPU来负责高效的图形渲染操作。
如今,CUDA的整个生态环境和GPU的地位发生了巨大的变化,人们通过CUDA环境开发程序越来越容易,越来越多的应用开始借用GPU来加速(不只是Adobe和视频等专业应用,甚至浏览器都在用GPU做加速),这使得GPU里的CUDA Core也开始类似CPU一样变成了通用处理器。与之相比,老本行的图形渲染和输出,遇到了新的难题——单纯依靠CUDA Core数量叠加固然可以提升一部分性能,但是制程工艺的进步已经愈发困难,那么去重新审视计算机视觉的需求,就变得非常重要了。
[email protected] (91.63 KB, 下载次数: 0)

NVIDIA做出了令人佩服的选择——在消费级的GPU上大胆引入Tensor Core
从AlphaGo在围棋上击败人类以来,A.I人工智能的火热就伴随着一个词“深度学习”(Deep Learning)。作为机器学习的一个重要分支,深度学习用卷积神经网络来处理负责的认知问题,是从计算机视觉、图形识别以及人工智能方法论的巨大飞跃。
限于篇幅,这里不科普深度学习的原理和“玄学”成分,单说TU102架构为什么要加入Tensor Core。 深度学习需要两个部分来为用户服务:训练部分(Training)往往都是A.I公司在自身的数据中心里完成——耗时几个月甚至数年时间来用海量的GPU做相关的训练——训练的结果往往是一个模型,一个数值分布表。人类几乎看不懂这个模型有什么意义,但是这个模型文件可以在同一个框架下,帮助计算机去认知和判断。
举个例子,AlphaGo训练了几年时间推出的第一个版本击败了李世石(AlphaGo Lee版本)——其形成的模型就是如何下围棋,这里面包括了在任何时候判断局势,并选择出胜率最高的一步下在棋盘上。而类似商汤科技(Sensetime),旷视科技(Face++)这样的公司,训练出了人脸识别的模型,通过API接口提供给手机制造商和美颜相机APP的制作者,他们就可以轻易的做出各类应用(这里就不展开了)。

很少听说有个人做训练部分的——成本和时间都不合适(海量GPU和电费)。但是个人玩家可以做深度学习的另一个部分:推理(Reference)。前面说的那些训练出来的模型和结果,如何得以应用呢?提供给用户做本地推理——而本地推理就有了性能高下之分,比如你用CPU来推理AlphaGo的模型和我用GTX 1080Ti的机器下棋,10秒一步肯定是GPU赢。 这也是为什么手机制造商要在手机里强调自己有A.I加速芯片(如苹果A12强调有生物加速芯片,Huawei强调自己有寒武纪的人工智能芯片来加速人脸识别),加速本地推理是A.I的一个重要部分。
说了这么多,大家应该明白了NVIDIA在TU102里加入Tensor Core的意义——让GPU的推理能力更上一层楼(GeForce系列不鼓励去做训练)。对于用户和玩家来说,我又不做人脸识别,图形识别,推理能力有什么用。这就牵扯到了伴随RTX 2080Ti发布的重要特性——DLSS。
DLSS全称是Deep Learning Super-Sampling(基于深度学习的超采样),是一种去锯齿技术。玩家们应该知道在很多游戏里可以设置TAA(还有早期的SMAA、FXAA等),和64倍超采样等反锯齿特性。这是源于计算机图形学和数学——多边形渲染带来的不平滑,依靠超采样分析周边的形状来平滑过渡,消除锯齿。然而这样做有一些不可避免的性能损失,在渲染内容复杂的时候,GPU的开销过大会直接导致帧率的降低。
TAA这类算法的通性就是对每一帧画面上出现的元素进行全屏反锯齿,无差别的采样,渲染。这对于实时渲染稍复杂一些的游戏画面来说,对显卡造成的压力非常大。
为了解决这个难题,NVIDIA将负责深度学习推理的Tensor Core引入GPU,使得游戏在实时渲染画面的时候,根据画面内容和人所在意的细节来“有选择性”的反锯齿——说穿了就是原来的TAA是无脑的全部都反锯齿,不管你有没有在看,看不看得清。而DLSS则是“聪明”的反锯齿,只把画面里你可能会注意的细节来做反锯齿。
那么问题来了, Tensor Core是怎么推理出该计算哪一部分的反锯齿呢? 你看,我在这里说了推理,那么就有之前的训练——NVIDIA此次同步退出了NGX技术——在其自己的集群里和游戏开发商一起先就DLSS反锯齿需要计算哪些部分进行了深度学习的训练。而这些训练的结果就伴随着一次次驱动升级,被推送给玩家——Tensor Core就可以在越来越多的游戏里发挥作用,甚至是对原先的游戏来说,“越来越聪明”,帧率提升。
目前NVIDIA公布了未来将支持DLSS的25款游戏,其中就包括下面Demo图中的 最终幻想15。
image003.jpg (253.51 KB, 下载次数: 0)

如上图所示,GTX 1080Ti不支持DLSS,开启TAA反锯齿之后,结束时画面帧率33.6,总分只有377。得益于CUDA Core的增加,RTX 2080Ti用TAA模式的结束分数是4330。而开启DLSS之后,RTX 2080Ti的结束画面停在了47.7帧,分数高达5871
可以看出,有了深度学习加持的“脑补”型反锯齿效率要高得多——Tensor Core功不可没。除了拥有DLSS特性的游戏能用到Tensor Core之外,还有什么能用到GPU的这个功能么?有啊。比如在自己的电脑上玩任何有深度学习引擎的游戏——棋类游戏等等。
Leelazero 2080Ti vs 1080Ti.jpg (191.11 KB, 下载次数: 1)

测试数据总结如下表:
[email protected] (122 KB, 下载次数: 0)
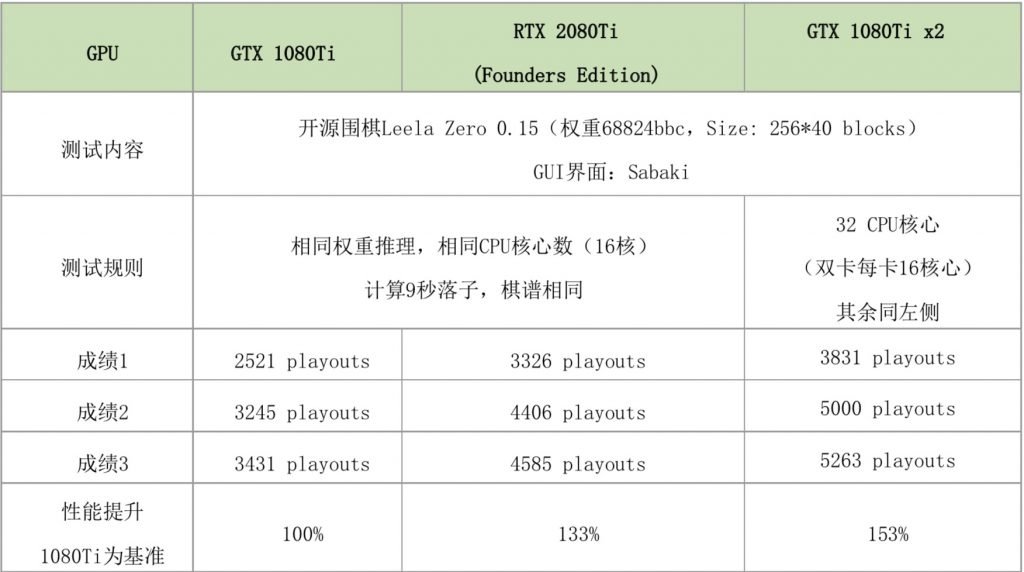
笔者用现在流行的民间“AlphaGo”做了推理测试,RTX 2080Ti大概比GTX 1080Ti的推理性能提升了33%左右,Tensor Core功不可没。即便是与SLI的两个GTX 1080Ti相比,单卡RTX 2080Ti也仅仅落后20%——这性价比没谁了。
实时光线追踪不再是好莱坞神迹光线追踪是个老话题,喜欢研究的读者可以搜一搜网上的帖子,很多文章有列举和科普NVIDIA的相关图片和资料。这里笔者只想举个例子来说明一下光线追踪和传统对图形的光影做渲染的区别:
在传统的光影环境中,GPU用光栅去处理光影关系,也就是将3D的图形映射投影到一个2D的平面上,然后去处理每一个点应该什么亮度,什么颜色等等。这样在最后合成起来,就得到了一个3D的图像——这非常类似MRI(核磁共振)的切片式成像原理。但是问题也很大——如果写程序的人理解错了某个局部的光影,或者做的比较粗糙,我们一眼就能看到问题——你并不能指望这种方式无限接近真实的光影。
而光线追踪则是我们平时在现实生活中看到东西的样子——光线从光源发出,可能是灯,可能是太阳,射到物体上再反射到我们的眼睛里,于是我们看到了亮部,暗部,颜色等。光线追踪就是要模拟这样的过程,只去定义光源和材质的物理性质(反光程度、漫反射程度等)。
做个比喻,光栅化的处理图形,相当于出题的人知道每一个题目的答案(或者是脑补了答案),然后把做题过程和答案都写好,你照着抄一遍。而光线追踪,则是出题的人告诉你一个或几个公式,根据这个公式去套题目吧。
[email protected] (119.23 KB, 下载次数: 0)

光线追踪开(下图)与关(上图)的区别然而,自然界中、游戏中,并非只有一个简单的点光源——你的显示器发出的光,你的杯子反射的光,旁边路过的汽车的玻璃反射了光——非常复杂的多光源场景,怎么追踪?这是什么样的计算量!!
所以业界在提到光线追踪的时候,往往都是好莱坞的CG大拿们做离线的运算——这就是为什么一个影片的后期特效可能要做几年时间。而如今,实时光线追踪成为了现实。

与GTX 1080Ti的2.8-6.2帧相比,RTX 2080Ti最低26.7帧,最高45.3帧令人动容(RT Core加入之后的光线追踪性能得到了无与伦比的提升)
image006.jpg (179.76 KB, 下载次数: 0)
笔者非常喜欢NVIDIA的这个星球大战主题的DEMO(Reflections Demo)——法斯马队长被两个白兵在电梯里调侃。在今年3月NVIDIA在Game Developers Conference上就运行过这个Demo,只不过那时候这个Demo运行在NVIDIA DGX Station工作站上,驱动它的是4个GeForce Titan V——而如今只需要一块RTX 2080Ti即可。
10月3日,微软刚好发布了Windows 10的十月更新补丁,其中加入了DirectX Raytracing(DXR)光线追踪技术,而NVIDIA目前是全球唯一一家支持实时光线追踪的显卡厂商。对于正在玩“古墓丽影:暗影”的玩家来说,可以第一时间体验到其中的妙处。
一个容易被忽略的小细节
RTX 2080Ti有一些非常有意思的小细节,首先是NVLink的加入——这是最早NVIDIA应用在Tesla企业级计算卡的技术,非常高的带宽旨在克服PCI-E总线那可怜的100Gb(注意是小b)带宽瓶颈。与之配合的是数据中心领域的OpenPower联盟以及NVIDIA自己的DGX系列GPU服务器,这是题外话。
但是两块RTX 2080Ti桥接起来,仍然叫SLI——至少驱动里是这么写的,NVLink为两个卡提供了50GB/s的单向通信带宽(双向100GB/s,注意是大B,和小b的换算是8倍的关系)。
image007.jpg (78.45 KB, 下载次数: 0)
NVIDIA此次在图灵架构上大刀阔斧的革新,让笔者想到了2010年“Fermi(费米)”架构横空出世时的情形,一样是市场上支持新特性的游戏不多,架构全革新以开启CUDA Core通用计算的未来。在某些测试中,市场上的声音都认为费米改动太大,未必能够君临天下。8年过去了,CUDA的地位无人撼动,“费米”之后的“开普勒”,“麦克斯韦”直到“帕斯卡”一代代卡皇黄袍加身,需谨记“先帝”——“费米”。
如今“Turning(图灵)” 架构的革新又一次开风气之先,而且这一次上下游合作伙伴都明显能看到其巨大的进步空间——这大概也是为什么GeForce系列显卡要把名称从GTX更改为RTX的原因。
附测试环境:
GPU:NVIDIA GeForce RTX 2080Ti,GTX 1080Ti
CPU:双路至强 E5-2697 v3 2.6-3.6Ghz(14核28线程 * 2)
Motherboard:ASUS Z10PE-D8 WS 双路工作站主板
Memory:64GB (16*4) DDR4 3200 ECC 内存
Disk:2* 256GB Intel P730 SSD (RAID 0 阵列) LSI 阵列卡
PSU:AX1200i 电源
声明:
本文原创,有转载请发信申请笔者同意(尤其是微信)公众号和第三方媒体,谢谢。
文中素材为笔者亲测所得,原始数据、图片和相关视频文件均保留作为证据,如需引用,请发信获得授权。
评论
沙发。
另,本文也发在了本人的私人博客上,稍后还会发在我的微信公众号上,博客注明了原贴发在这里。 特此说明。为避嫌,这里就不发地址了。
针对有网友问的深度学习训练的性能,这里也贴出来,与 GTX 1080Ti 和 Tesla V100对比:
WechatIMG801.png (17.8 KB, 下载次数: 0)
软件版本是 TensorFlow 1.1.11,CUDA 10,Batch size 是32和64
WechatIMG786.png (10.06 KB, 下载次数: 0)
大幅超过 1080Ti,期中在 Batch size=32时,VGG16的性能超过了 V100.
另外,对于推理层面,有大佬 @我輩樹である 指出本文的错误(14楼):楼主你的结论有问题,在发微信前最好改一下。
这是这个象棋软件作者的回复,就在前几天。
https://github.com/gcp/leela-zer ... uecomment-439654245
因为授权的问题,该软件不会支持cuda,自然也不可能有tensor core的调用代码。你的测试其实测的就是sp性能。opencl甚至无法开启turing卡的双倍半精度。
“The situation with the RTX cards has made this a real issue though. It seems that their fp16 capability isn't exposed to OpenCL.”
评论
非常高的带宽旨在客服PCI-E总线那可怜的100Gb(注意是小b)带宽瓶颈。克服
评论
恕我直言,这也叫“深度”解析?
评论
多谢多谢,改正了
评论
指的是深度学习的部分——深度
评论
还是没有看到哪里有deep learning的测试。因为rtx 20系卡的tensorcore的mac(乘积与累加)操作的位宽减半,所以我比较感兴趣是否影响到半精度的training性能,楼主方便的话测试一下。用cublas测试比较准确。
评论
码字不易,但全文干货就只是跑了个围棋?而且这个也不能算干货吧...别的内容和发布会ppt也没啥区别啊
评论
我就想知道星球大战的运行Demo哪里有下。。。
评论
这种科普贴实在太喜欢了
评论
这个leela zero看上去是opencl的程序,opencl怎么开tensor core,tensor core是cuda专属的。而且leela zero也没有哪个地方说明开启了tensor core,tensor core的开启条件很苛刻的,需要coding支持。楼主跑的是第一方还是第三方的leela zero,github上有人实现过cudnn based leela zero,楼主跑的第三方的么?还是楼主自己改过程序了。
如果哪里明确说明了开始tensor core,请贴个地址我看看。
https://github.com/gcp/leela-zer ... uecomment-437571559
评论
楼主你的结论有问题,在发微信前最好改一下。
这是这个象棋软件作者的回复,就在前几天。
https://github.com/gcp/leela-zer ... uecomment-439654245
因为授权的问题,该软件不会支持cuda,自然也不可能有tensor core的调用代码。你的测试其实测的就是sp性能。opencl甚至无法开启turing卡的双倍半精度。
“The situation with the RTX cards has made this a real issue though. It seems that their fp16 capability isn't exposed to OpenCL.”
评论
在中间,用 Leela Zero 做了围棋的推理测试,对比了1080Ti。
其实我还做了 TensorFlow 和 Matlab 的测试,考虑到太行业了,没有写在文章里。
你感兴趣我可以补一下结果在2楼
评论
Demo 并不公开,需要成为 Nvidia 的邀请测试人员,才会一对一的给所有 demo 的下载。因为被记录了身份,我也不好公开放到网上。
和官方的那些4K 壁纸一样,比较难
评论
你说得对,我在写这个的时候还没有看到这个文。只是推断了33%的提升除了晶体管提升,应该有 tensorcore 的作用。社区里其实有人做 CUDA 版本,但是还没有支持到 CUDA10.
由于另一个支持 CUDA 的围棋叫 AQ 的,已经停止更新快一年了,所以没有去做相关测试。
不过1080Ti 和2080Ti 都一样的标准下,推理的提升还是明显的(1080Ti 我用的还是非公版的)。
我把你的帖子贴2楼哈。
评论
精彩的是:As much as I'd like to say "fxxk NVIDIA, let them make decent OpenCL drivers" the current GPU market situation isn't going to let that work out for the foreseeable future. And we'll run at half the expected speed for the most popular cards. That's not good.
结合楼上回复的意思,中心思想是,此围棋程序并没有体现tensor core的性能。原因在于N不开发对应的Opencl接口。暗示其实有两点:1,没有用Tensor Core一牛逼至此,开放了可以秒天秒地;2,N无意开源造福大众,大家还是散了吧。
CUDA就是用来赚钱的,不是靠买卡赚钱,是苹果商店式的垄断经营。N也没有立牌坊的意思。RTX就是游戏卡,楼主的标题真搞笑。
评论
很多做深度学习的公司,如我提到的商汤,甚至阿里巴巴,使用 GTX1080Ti 来做训练,因为 Tesla 太贵。所以 RTX 看起来是游戏卡,官方也希望他做游戏卡。我测试的下棋程序也是游戏。做深度学习推理的游戏也是游戏。
CUDA 的授权问题其实并不完全和作者说的一样,他是为了用一套代码支持所有平台。OpenCL 显然是好选择。
反例是,Github 上的日本围棋程序 AQ 就只能使用 CUDA 库,而不支持 OpenCL。
打开 TensorCore秒天秒地不至于,这种事官方不会做,消费级的不愿意,企业级的不在意。
评论
学习了 记得中后期Google在做解释的时候 好像说AlphaGo 2.0类型的AI 不需要再去做人类棋谱的Training了 是否可以理解成之前已经通过Training做好了模型 然后通过推定去做决策和AI对AI的Training呢
评论
是强化学习。
指的是 AlphaGo Master 版本之后的 AlphaGo Zero,从零开始就没有学习现成的棋谱,给它规则,让它随机随便扔子,然后自己根据胜率动态的淘汰和迭代。 大概2个小时的训练,它就完成了从刚学棋的小孩到人类业余高手的进化,3天的训练之后(1000个 TPU的集群),达到了和李世石下棋的 AlphaGo 的水平,40天的时候,超越了战胜柯洁的 AlphaGo Master。
具体可以参考 DeepMind 的论文。
LeelaZero也是如此,可以看下面这个自己学习的权重更新图表,分布式的训练让所有社区里的人可以参加,从去年这时候到现在,一年时间已经攀升到差不多等于 AlphaGo 的水平了。
[email protected] (118.48 KB, 下载次数: 0)
评论
跟显卡挖矿不如asic矿机挖矿一个道理,指令集单一或者直接用电路逻辑体现算法,比gpu有高能耗比面积比,缺点支持的计算类型少,在其他场景下就是摆设,像asic矿机只能挖矿,tensor只能推理 rt光追只能计算交点,gpu以上都能干但是能耗比差
tensor人工智能推理 rt光追市场钱景确实很大,对游戏提升有帮助,所以nv股东们10年前就投钱研发gpu+asic的图灵架构,总投入估计能把你送出银河系,所以黄卡滞销帮帮我们
ps 总投入估计10倍amd市值所以还指望amd做出光追这东西?
评论
哦哦 那我再去搜索一下论文 多谢指教 非常感谢
评论
想问一下tensor core是只能做reference么,training效率怎么样,学生党想自己买块便宜显卡做一些小的training上turing的意义大么
评论
Tensorflow可以用CUDA10了么
评论
好文,一字一句的读完了。
评论
遇到高手请教一下:本人科研狗一枚,99%实验1%编程。属于拿来应用主义。硬件:Z4+P2000 工作站 + HPC(52/top500). 目标是通过深度学习建立一套数据分析工具。不知道从何入手。倾向于Python。可否指点个明路? CUDA的开源工具好像很有限。
评论
搭车同问~
评论
Nvidia 并不鼓励个人用户或者公司用 GeForce 系列显卡做Training,所以如果你用 TensorFlow 或者 Caffle 去做训练,会发现只调用了普通的 CUDA Core,而新的 Tensor Core 和 RT Core 基本在怠工。
如果 CUDA 官方打开了对 Tensor Core 的支持——如企业级的 Tesla T4,就是图灵核心的卡。那会极大的影响自己的生意——V100和 T4可是很贵很贵的。
评论
强烈推荐一个网站和 Pytorch:
http://tflearn.org/ 极度适合学习和入门,如果你有耐心重复一遍网站上的所有安装,操作,算法,案例代码。你就熟练了解了整个深度学习的构成和经典思路。
因为原生 TensorFlow 的调优非常繁琐,往往你训练几小时看看结果不理想,去调参数的时候,要花很久时间。所以大家就发明了 Pytorch这种基于 Python 语言的深度学习库。很棒。
另外,建议用你的工作站来做本地调优,训练一晚上看看结果,如果识别率上去了,代码可以,再把海量数据和你的算法传到超算集群里去。要注意的是,建议用 GPU 做训练,如果你的 集群是纯 CPU 集群(top500更新了,52名是美国机器),就不太好,主流训练都在 GPU 上进行。要快几千倍。
试试阿里云的 V100机器,租几小时也就几十块钱,有兴趣还可以试试 Google 的 TPU
评论
非常感谢。很有用的提示。准备照着这条路走了。
#52是我们实验室内部的机器,刚升级完就跑分排名,我们这些用户还没用呢。所谓政绩工程是也,古今中外都一样。堆了一坨P100,会CUDA没几个。不过大牛们好像都去抢橡树岭了。
评论
没有官方的发行版,但1.12以后已经兼容了,可以自己编译。
当然可以training,深度学习算法对精度没有非统计学算法敏感,tensor core可以做半精度训练(reference反倒是附带的),turing之后的tensor core还包含int8/int4的倍化性能, 虽然是为推理性能准备的,但也可以做训练,只不过不适合任何算法,训练需要一些trick。
比如必要的时候使用precision refine补强精度损失。
评论
只要符合一定编码规范就可以使用tensor core。tensorflow也支持tensor core。
https://www.chiphell.com/thread-1839986-1-1.html
至于rt core,它本来只是用来算ray tracing和bvh碰撞的专用核心,和计算mac的统计学算法没有直接关系。
评论
多谢分享!
评论
楼主你既然要写科普就好好调查下。逛这个坛子的我知道的ai phd就至少5个。
评论
有空研究一下。。1.12好像不能在Windows下用cmake了,bazel还没试过
评论
不推荐在windows下搞这些。
评论
橡树岭未必合适。
你对RDMA熟悉么,现在的深度学习都需要你熟悉一下网络的这些技术,NV的GPU都自动支持RDMA,配合网卡可以提升学习的效率。TF 1.1以上都支持
评论
大牛,谢谢各种回答和补充信息。
我在学习你的帖子,受益匪浅。
我是业余的深度学习爱好者,下次测得时候就和你咨询。
评论
基本上算是小白。路还长着呢。在编程方面本人属于装机型技术人员,凑在一起能给我干活就行。至于怎么做芯片电路板,只求略懂一二。 电路 电子 维修 求创维42c08RD电路图 评论 电视的图纸很少见 评论 电视的图纸很少见 评论 创维的图纸你要说 版号,不然无能为力 评论 板号5800-p42ALM-0050 168P-P42CLM-01 电路 电子 维修 我现在把定影部分拆出来了。想换下滚,因为卡纸。但是我发现灯管挡住了。拆不了。不会拆。论坛里的高手拆解过吗? 评论 认真看,认真瞧。果然有收
·日本中文新闻 日本26年新成人预估仅109万 与去年并列历史第二低
·日本中文新闻 日本皇居新年参贺突发裸奔事件 男子涉公然猥亵被捕
·日本中文新闻 印度宣布超越日本成为全球第四大经济体
·日本留学生活 在熟悉的城市,遇見不一樣的感受
·日本留学生活 求购一些水电燃气话费等公共料金请求书
·日本华人网络交流 制造信息垃圾的产业,这种现象在日本尤其普遍。
·日本华人网络交流 美军入侵 委内瑞拉领空 并非零伤亡
·日本华人网络交流 年末采购食品,恰时间就能全半价。
·中文新闻 马丁·克鲁内斯 (Martin Clunes) 在新剧中变身休·爱德华兹 (Huw Edw
·中文新闻 当朋友们讲述他们对他们的阴谋感到震惊以及他们如何向他们隐