
ssp_406_575px.jpg (50.39 KB, 下载次数: 0)
ssp_404_575px.jpg (69.11 KB, 下载次数: 0)
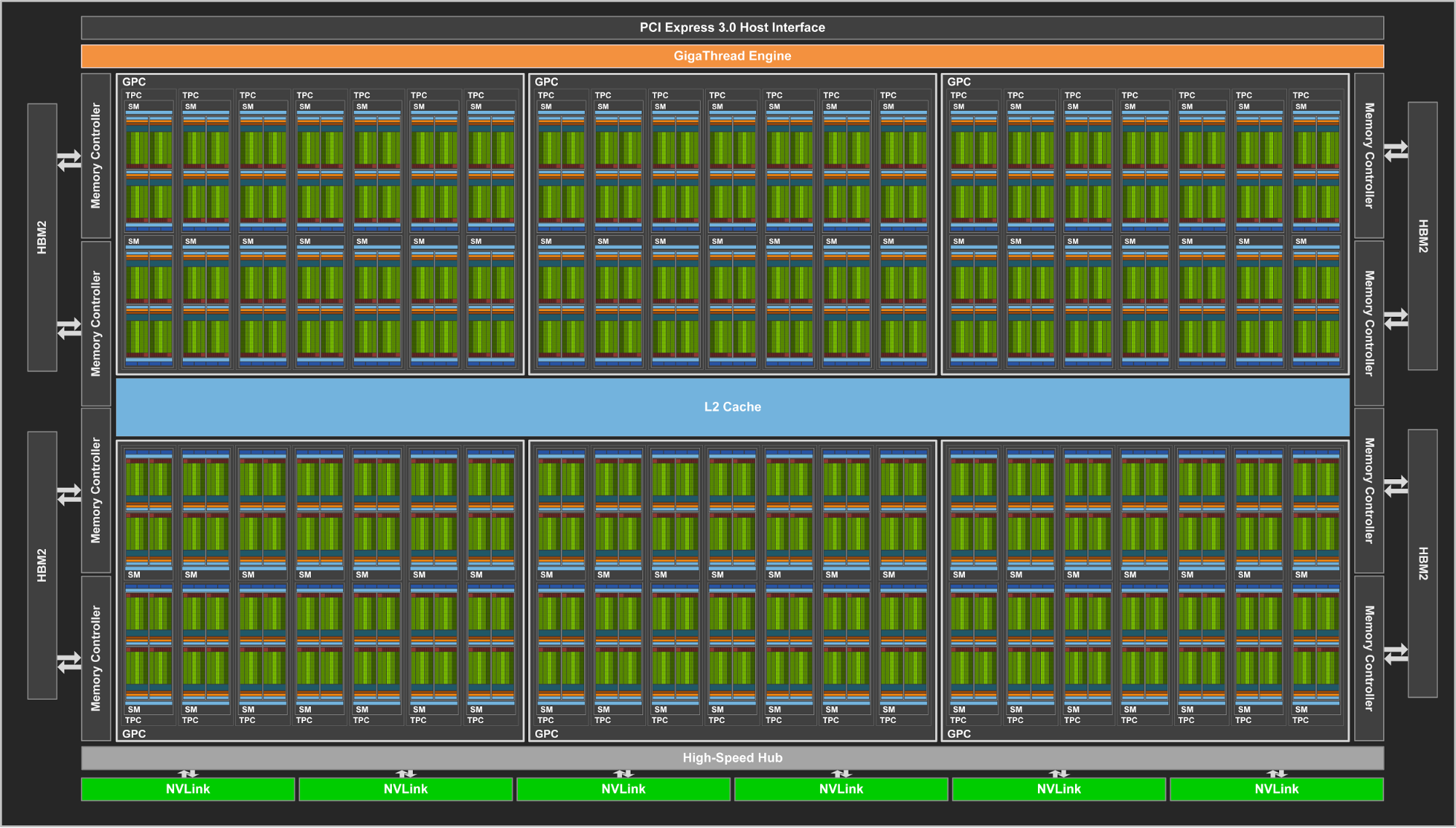
815mm^2, 210亿晶体管, TSMC 12nm FFN。
VCZ声称满血GV100是5376CUDA Core。
https://videocardz.com/69378/nvidia-announces-tesla-v100-with-5120-cuda-cores
NVIDIA-Volta-GV100_1.png (376.09 KB, 下载次数: 0)
评论
HBM2只给计算卡用吗?消费级还是GDDR6?
评论
15t 5120sp 频率应该不高吧
评论
酥麻欢声笑语中打出GG
评论
目前来看很可能明年旗舰卡上HBM2,中高端是GDDR6
评论
Anandtech Ryan Smith的文字直播
GV100
210亿晶体管
面积815mm2
5120 cuda
7.5T FP64
15T FP32
加速混合FP16和FP32的矩阵乘法(?),等效120T "Tensor flops"。貌似只是4x4矩阵,估计是鼓励大家使用2x2卷积核。

最新消息,4张GV100的personal dgx station仅售$69000,功耗1500W。由此推断每张GV100一定在350W以下,更可能是300W以下。

评论
没有吧,5120sp,15TFlops的话就是1.5GHZ左右。
评论
1464MHZ,看来没痔变
评论
这货对convolution net的优化非常深入,以后想买游戏卡当计算卡可能越来越难做到了。
评论
...频率没质变。。但是这个性能。。15TF,,,如果12NM功耗能压到GP100的程度。。啧,,又是40%大提升
天下武功,唯快不破。正高一尺,邪高一丈。苏妈死关已久,黄老邪却又一次突破极限
评论
880mhz左右的hbm2...
评论
DGX-1集束核弹头
评论
vcz说gv100实际有5376cuda(84sm),只开5120cuda(80sm)
https://videocardz.com/69378/nvi ... ith-5120-cuda-cores
评论
会不会又是boost到1900以上的?
评论
mx390A0.png (97.18 KB, 下载次数: 0)
评论
QQ图片20170510184350.png (350.09 KB, 下载次数: 0)
单槽卡,功耗150W,不知什么版本
评论
进步真大。。。。
评论
bVobYT.jpg (202.03 KB, 下载次数: 0)
评论
5120/3584..1.42
15/10.6..1.41
BOOST肯定继承的,频率应该也差不多
评论
21.1B,21100M,815MM
2588万每平方毫米?
长进在TDP?
如果旗舰卡。和次旗舰高端卡不能上12NM。进步可能要小一些了,比如~700系?越算越感觉下一代80会是TTXp水平
评论
会不会今年下半年就出了啊,竟然公布的那么早
评论
personal dgx,穷逼也买得起的计算卡。
评论
q3出这个 GeForce 起码明年了
评论
老黄又造新词 那个tsenor有人来解释一下吗
评论
900mhz 这么看我又对vega的显存频率打问号了
评论
那要看苏妈那边给力不给力了 大概率还是gddr6
评论
不是新词,就是cuda运算中代表一种op的词汇,一般定义tensorDescription。数据也可以用tensor描述,有各种维度,操作也可以用tensor描述,是一种统一的表达,这个词汇来源应该是物理方面的。cuda的运算就是各种tensor运算。
评论
评论
那么问题来了
Geforce系列能享受到这40%的大提升嘛
评论
混合精度运算,跟以前披露的int8 * int8 + float16 = float16一个概念。但这里的是training中用到的。
照比GP100与GP104性能差,我想应该是可以的,,就是核心要大了,估计80就是80TI的核心了。核心就是晶圆就是钱,老黄会在优势下返利?可能吗? 这就要请我们的苏妈打一张好牌了!,否则洗白白了等挨宰吧
评论
老黄不是喜欢自我超越自我实现么?优势返利简直驾轻就熟,这次1080ti不就是回报社会。
评论
还是想不通,那个tensor flops是怎么算的。以及发布会提到的4x4卷积硬件实现?
评论
只能猜猜看,等他发布进一步资料。
这是int8的图。
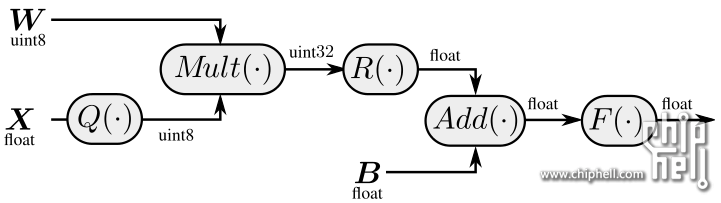
其实是类似的,首先是alu和寄存器硬件上支持混合精度,新的指令集。其实是Tegra就引入的技术的延伸。
然后重复利用了低精度只占用一半的地址区域,加速运算(一个高精度地址区域塞入两个低精度,同时算两个)。
4*4不太懂具体指什么,4个kernel一起算出4个featuremap?
查了下nvidia的博客,流程跟int8一摸一样:
image11.png (27.32 KB, 下载次数: 0)
它没写下一轮计算的时候,fp32被量化成fp16的过程(图1的q函数)
评论
老黄回报社会之种田韭菜计划 ,时间就是金钱,金钱就是生命,先是TTXP收割,再是1080TI收割。TTXp又割,然后下一代80,TT差不多SP,显存更快更强。则性能小胜,显然又是一波收割
评论
4*4矩阵乘法感觉是针对2x2 kernel的卷积。cuda里卷积还是写成矩阵乘法的形式吗?不懂cuda瞎猜的。
评论
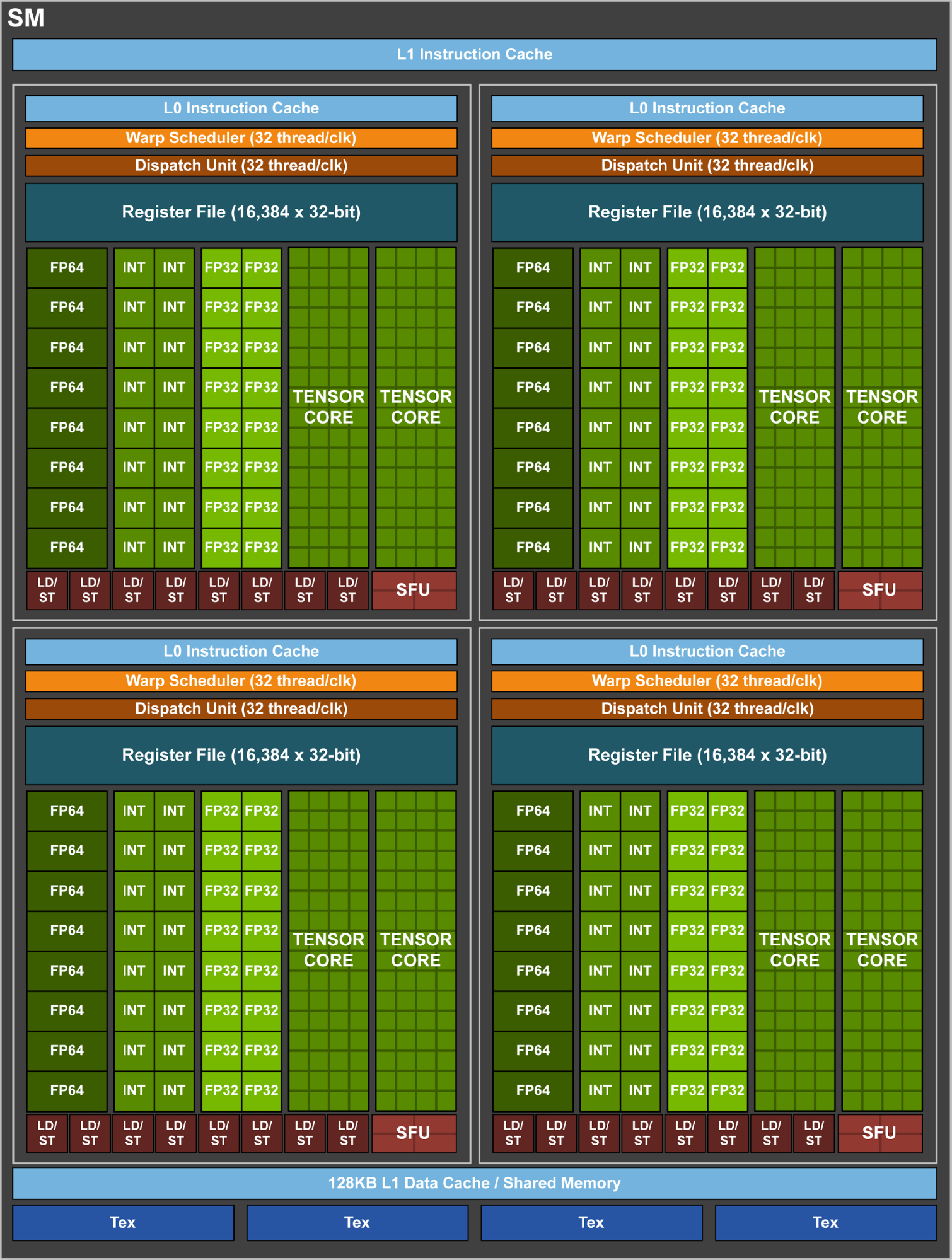
看了下nvidia的博客,是这样的:
image4.png (164.21 KB, 下载次数: 0)
它的tensor core内部是这么设计alu的,可以做4*4(input) * 4*4(kernel) + bias(4*4),一次性完成(16个数值的卷积运算)以前用cuda核一个个遍历运算的过程(这个过程你自己也可以写kernel函数(这里是指cuda的kernel function,不是cnn的kernel),模拟这个批量运算的过程),并且可以混合精度,这其实是一个硬件的优化,跟软件和代码都没关系,网络该怎么设置怎么设置,当然用4*4的kernel来可能可以做到极致性能,当然硬件的性能是其次,没有必要迁就,网络的性能最重要。如果kernel不是4*4,它可能自动帮你拆分,分批运算,多了一个自动batch的处理。
这可是一个相当大的核心,而且这同样可以用于图像处理,游戏也能用的。当然下放的时候会不会阉掉,是问题。
评论
https://devblogs.nvidia.com/parallelforall/inside-volta/
1,tensor cores支持混合精度,所以在运算时比p100的核心有利这是肯定的。
但不知道为什么纯粹的单精度运算,tensor core和普通的cuda核,大家都是并行,还是tensor core效率高一些。文中的意思还是特别优化(Tensor Cores and their associated data paths are custom-crafted to dramatically increase floating-point compute throughput at only modest area and power costs)。可能有硬件分包和软件分包的区别。
2,新的volta引入了新的,全线程独立的simt(单指令多线程)模型,没有调度器阻塞的过程。
新simt模型为每个线程设计了独立的计数器和调用栈,而pascal是整个程序公用一个,解耦了计算和数据调度(读写取)的依赖。
评论
这性能真是要爆炸了,AMD给力点吧。。。。
评论
新simt模型是否意味着异步计算性能要爆炸?!
评论
要是talk开头提到的用deep learning加速的ray tracing能集成进游戏的话,下代显卡就有它了。neural net在消耗计算量和提高酷炫指数方面确实很有前景。
评论
现在的异步性能难道还不够爆炸么?这个很可能也只是为科学计算准备的,普通的计算可能根本阻塞不了调度器。
评论
老黄这个时间发布这个是在暗示苏麻麻那边的新玩意儿有点意思?
评论
要坚信苏妈the poor volta
评论
blog里的这段话你看懂了么?每个周期,tensor是32个mul+32个add,还是64个fma?要怎么和这架构对上?
评论
N=4矩阵乘法需要N^3次操作,应该是64个fma
评论
刚才想了一下,应该是4组同时计算,每个如图是4x4的卷积(mul+add)
矩阵的话,我觉得可以64的loop unrolling。blog说tensor的混合矩阵乘法性能,是fp32的6倍左右
评论
每一个A的节点到D是4次mul + 3次plus(acc),加上偏移1次,就是4次mul + 4次plus,16个节点就是64 + 64(64mul + 64plus = 64fma?)。
这是把加法单独拿出来算一次op,如果它说用acc代替加法,其实就是4*mul + 1*acc(不论多少,就一次) + 1次plus。
我不知道是否有这个指令,一次合计几个地址上的值。
评论
所以其实就是…
除非苏妈的Vega真的能摸1080Ti的屁股不然妥妥的没戏…嘛…
评论
这样也挺好的啊,永远不用买第二块1070了稳稳的蹲在这等着下一代80(≧▽≦)或者80Ti
评论
之前忘记D其实是矩阵了。。。
我感觉这要看这个tensor的指令集能有多灵活,感觉应该是不能直接做成64个loop unrolling,不然为啥要设计成一整个单元。
你值得a->d,4个mul+4个plus是按照一行4个单元来推算的么?
评论
是啊。
做loop unrolling要一定的逻辑电路来展开,这里只是堆alu,设计逻辑电路在这里太复杂了。而且并行度已经足够高了。
评论
…老黄为什么总能diao得超乎所有人想象?在大家已经觉得本代产品已经巅峰的时候?
评论
楼上喊苏妈苏妈的,我就想问苏妈跟这有半毛钱关系吗
评论
感觉AMD现在就靠2000以下显卡赚钱了……
评论
问题是这计算卡已经整合了这么多东西了,游戏卡该砍的一砍,又宇宙无敌了
评论
下一代的70系列大于等于上一代的80ti这是很稳的……从来没有例外过。
评论
我就知道要出来这个图!肯定是妮老婆让你发的!
苏妈在欢声笑语中打出GG,阿三什么的还是和吹的牛逼s一起去死好了
难不成vega变成又一个推土机……果然鱼有两面……
评论
阉一阉出个titan xv,车翻vega20……
老黄已经准备统治这个市场了,phi完全不够看
评论
咦?所以Geforce每代提升其实都巨大?
为啥我一点感觉没有…核心面积增加33%左右,性能提升50%?
评论
黄金Telsa帅不帅少年们快来充值

评论
刚才看了下架构图,简单说一下个人的看法。有不对请指正。所谓的TSMC 12nm其实也就是个噱头,晶体管密度和GP102类似。
Volta GV100的SM相对于Pascal GP100来说,差距并不是很大,如果说Pascal单个SM有四个CU的话,那每两个CU就共享一个Texture/L1 Cache和4个TMU单元,共计两块。而在GV100中,单个SM里只有一个Texture/L1 Cache和4个TMU单元。这样的设计其实是回归了类似原本SMX的设计,即单个SM只集成一个,想必老黄又大幅度提升了TMU的效率。
缓存方面,L2缓存提升了1.5倍,单个SM分摊的L2缓存更多了,但是单个SM的寄存器缓存大小没有变化。
众所周知Pascal是基于Maxwell优化频率的产物,那意味着优化Maxwell架构的工作(即Volta)在很久就开始了。
再看下实物。GP100的理论值为250W,而4个GV100不超过1500W,两者频率类似,就是说单个SM的功耗原地踏步了。
总结:老黄这次的架构改进还是比较少的。不过,单位晶体管可以塞进更多的SM单元了,效率也有不少提升,如果Pascal用了72亿就达到了GTX 1080的性能的话,想必Volta只用60多亿就可以实现。
评论
现在是不是老黄已经领先农企2代了?
评论
太遥远了,估计和gp100一样永远不会下放到图形卡
评论
架构上看,GP100是pre-volta,GP10x是re-Maxwell,不要混起来说
另外,GP100/GV100都是300W
https://devblogs.nvidia.com/parallelforall/inside-volta/
LD/ST在的,而且per SM的数量应该是翻倍了

评论
LD/ST还在的,哪里取消了
评论
不好意思,刚才我发帖没看到这张图...
评论
其实V架构还有很多资料还没公布 ,等接近上市的时候 会有更详细的报道吧
评论
我即使是死忠A粉,但也不得不承认老黄是精明的商人和技术人员,近几年都能掐着农企出好卡,其实我觉得现在nvidia的目标是用通用计算、人工智能方面的收入来补贴游戏卡的开发成本,毕竟商务领域的利润才是大头,用高利润的产品来带动整体显卡架构体系的进步也是不错的策略,貌似现在农业也开始这样干了
评论
不要拿Gaming的Pascal去比,那些就像你说的是Maxwell优化,GP100可以说是完全不同的Pascal(或者说原型版Volta)
比如GP100就是4 TMUs per SM,不是GP10x的8 TMUs per SM;GP100也是64 cores per SM而不是GP10x的128 cores per SM
GP100的架构图,跟GP10x不是一个路子的
http://images.anandtech.com/doci/10222/gp100_block_diagram-1.png
https://www.techpowerup.com/revi ... al/images/arch1.jpg
评论
这又是xx70干翻80ti的节奏啊
评论
哲学架构的诞生
评论
话说下代显卡架构事那个物理学家?
评论
当年4870打得gtx480回炉重造,很快设计组访谈就出来了。maxwell架构把gcn憋了这么多代,到现在连设计师是谁都查不到
评论
我只想问我将来的MODEL 3会上这张卡吗?
评论
和异步计算没啥关系。就是个软件模型而已,占两寄存器来放pc和栈指针。
评论
老黄太可怕了!!
苏妈分分钟要倒闭了
不是刚出入门级1030吗
评论
高亮一条被很多人忽略的新 feature,整数运算有了自己单独的 datapath。换句话说,从 Volta 开始,Compute 相对于 Graphics 在 Nvidia 的 Arch 中具有了相当甚至更高的话语权。
评论
四缸不够,八缸来凑,转速不够,提高转速。本质上来说并没有任何突破。
评论
路過看看
我這1080ti都沒著落呢
评论
这流处理器数比pascal还少啊,而且5120÷3除不开啊
评论
这得看你怎么定义每一代咯,你要把一个架构的小核心大核心算两代那就不大了~~
评论
完全同比例計算的話
GV104 完整版的應該會有3584SP
评论
纠正一下,是HD5870
评论
酥麻要打这玩意,必须得拿出≥18TFLOPS单精的卡来。
评论
所以说啊,老黄比牙膏厂厚道的就是,对手不给力,自己不能停滞不前啊。
评论
但是阴特尔也不是在对手不给力的一开始就停滞不前,而是把性能甩开两倍多时停滞不前,谁也不知道老黄把双芯Vega甩开两倍之后还会不会像现在这样
评论
因为他一直在努力,他的对手就是自己!
评论
瞎说,GTX480最大的问题是功耗,不是性能。
他的对手是intel的众核和google的tpu好么,这两玩意可不是随便就能战胜的
评论
特斯拉目前的价格要一百多万RMB吧,相当于一套房子
评论
这是台积电能造的最大的gpu,工艺代号12nm FFN,这里N是nvidia的意思。超过18Tflops的目前来看只能多卡。这从另一个侧面也说明堆规模已经不那么可行。
其实amd早就抱紧了矿工大腿,最近fury也好rx480也好,以及未来的vega,都是弱核心重内存,用来挖以太币的......这也算一种胜利吧?
评论
到时候一堆低价矿卡又把自己的潜在客户抢了
评论
并非是老黄高瞻远瞩,事实是老黄符合了历史进程。
当年老黄把图形卡设计成gpu,设计成gpgpu的时候,就是受到众核(many-core)架构的影响(当然他并不是第一个受到影响的,这个理论其实业界都懂),众核架构和多核架构的区别在于众核架构将晶体管多用于堆积alu,而不去做大且复杂的cache和逻辑控制电路,它是缺少一定的定制化电路的(对比cpu),指令集也比多核架构的cpu要少很多,而是擅长蛮力并行运算,游戏渲染中所要用到的过程,比如材质处理,顶点运算坐标转换,光栅化等刚好这些处理正是需要蛮力算力而不需要太过复杂的逻辑运算,多是simd处理。众核架构曾经一直都是超级计算机采用的方案,从古老的ibm powerpc,ps4 cell,到现在的国产神威处理器,都是基于众核架构(集成其他理念)而开发的。
现在老黄在ai界的统治地位,取决于流行的深度学习一方面需要巨大算力,另一方面对精度不敏感(本身自带纠错,模型对正规化(normalization )的容忍度也很强),这也算是众核架构的重新归位。
话说回来老黄的统治地位来源于消费级显卡就能够做ai产品的超高效费比,如果在volta选择收网,那真是太让人失望了。
评论
HBM2/HBM3那都是给HPC用的,Geforce根本不需要ECC,所以用GDDR6足够了
评论
放心,老黄不会挤牙膏。 一代一代新架构,新产品会出来的。
评论
volta投入30亿美刀,足够把kd**ee,k***on,E**o一起送上火星!
评论
但老黄抓住了机会,volta是方向明确的设计。世界上很多大公司都在跟N竞争,N相比之下不过是个小公司,抓得住机会就已经是高瞻远瞩了。V100的价格也没有比P100高多少,你觉得收网是因为你看见了变态的提升而已,真的要收网我是不信不能再涨个五成价格的。不过我也就是看热闹,你们专业人士的担忧我也是不懂的。
评论
为什么要带上我!!
讲道理,老黄比牙膏厂进取多了
评论
农企在显卡方面落后的话也是从1080发布开始吧,之前还能和老黄较量一下
评论
fury怼980Ti就已经有较大颓势了
评论
这里收网是指阉了tensor core下放,这比阉sm更不友好,逼着你去买dgx。
评论
科技公司不创新,不搞新产品可能吗,有什么好大惊小怪的
评论
也许老黄到时候会出一个偏重tensor的芯片,减少FP32比例,基本砍掉FP64什么的
不过这种明显不是消费用途的东西,定价也不会良心的
评论
讲道理,这玩意和双精度一样,明显不是应该由游戏玩家买单的
评论
那是想要的太多了啊,tensor core不下放的话,消费级的卡依然保持了线性的性能提升,性价比一样高,下放到消费级就性能性价比全部爆炸了…P100也有ttxp没有的FP64,但你用不到不在乎,现在tensor core你用得到了在乎了,但其实它的地位和fp64类似…我不知道我这么说对不对…
评论
volta可不是40%…tensor core带来的可能是很多倍的性能提升…我的问题是自己也不懂张量运算什么什么的,也想知道这提升能不能应用在游戏显卡中…
评论
游戏卡只要FP32就够了,里面加了太多游戏完全用不到的东西了,都删掉,其实做成300~400MM2都比这东西游戏性能强
评论
想请教一下tensor flops性能强弱对游戏卡有可能有帮助吗?即使现在的API之类可能不支持未来有可能吗?(底层的东西我完全不了解,说错了还见笑)如果有还是可以期待消费级带tensor core的显卡的,并且可以期待游戏显卡的又一次大跃进,如果没有帮助的话消费级显卡怕是不会有tensor core了…可能就说明深度学习硬件已经基本成熟了,行业前期接近结束了,个体或者小团队的开发者的黄金时期过去了…老黄深知深度学习用户最在乎的就是时间与效率,所以才有了两代比80ti早一年半年的TitanX,价格再离谱也是大赚…
评论
ai界用不到双精度,但用得到tensor core,就算买tesla回来也是关了ecc用单精度跑的。精度补正和ecc软校验算法都自带了(天生自有),根本用不上硬件来做。
真正需要双精度的是各种仿真模拟运算,动力学,有限元这些,明显不是这几年的热点。
这么说吧,这几年ai的飞速发展,特别是模式识别领域精度的极大提升,跟老黄的让利有直接关系,当然这属于无心插柳柳成荫的,当年做cnn手写识别的时候cuda库都不完善,cudnn库八字没一撇,我开始读博的时候cudnn的初始版本里面还有大量方法只有header没有实现,老黄提供了一个好的平台 => 牛逼的人开始做出成果 => 老黄觉得有利可图 => 补全了第一方库 => 更多人参与进来 => ai行业开始极大发展。
你要明白消费卡可以跑神经网络对行业是一个多么大的促进作用。一夜之间,你就拥有了匹敌以前超算集群才拥有的算力,ng在google训练猫识别的时候用了16000个cpu,你现在轻轻松松就可以通过几张消费卡来实现。
目前ai的发展还在进行中,绝大部分识别任务都还没超过人类精度,现在选择收网,会让计算优势重新回到大机构手上,能够做出有力竞品的就会越来越少,每个行业都是这样的,参与到其中的智慧越多,发展越快,老黄让ai大发展也是这个道理,廉价消费卡让全球智慧参与到ai上来换来几年大发展,如果volta阉割收网呢。
小团队的产品做不过大团队(算力差太多) => 小团队觉得ai没前途了(搞不过买得起dgx的) => 转向别的方向 => 全球参与的智慧变少 => 行业发展停滞
老黄是让全球参与的关键人物,一手遮天。
评论
有参与感的人,体会是不一样啊。我作为一个吃瓜群众,以前一直觉得这种行业是大企业才容易有结果的,个人开发者有时候别说考虑到了,想都不一定想得到…现在读了你的体会,也想到了从古至今的一些时代和事情,想想确实百家争鸣更好,垄断与寡头从来不是褒义词。
评论
肯定是有帮助的,而且提升不亚于科学计算。本质上游戏的渲染过程也是一堆数值做并行的simd运算。当然也有可能不如科学计算,如果硬要说图像渲染和科学计算有什么区别,就是前者是有pipeline的,会卡在某个最短的木板上,是一个同步运算的过程,光一个部件算的快也没用。
评论
那我猜老黄不可能不懂的,他做的东西方向性很明确,比如GTX680大刀阔斧,HWS说砍就砍了,到现在都没人敢说当时想得到吧。V100我感觉还是一个“全能”并行处理器,说是为深度学习设计依然带1/2的FP64,总之整合了太多东西。既然老黄已经做了这么多了,原理也相通,我不相信他不会用在游戏卡上的,而且多核CPU也越来越普及,相信可以很好地配合计算单元算力的提升,哈哈。Titan当年出来的时候就有报道说可以写邮件向NV申请,个人开发者可以打折购入,可以期待未来也会是开放的。雷军说过一句话,希望可以做自己喜欢的事,顺便把钱给赚了。老黄如果继续做下去,说不定可以把“喜欢的事”改成“伟大的事”。乐观地期待新Titan会是什么样的吧!
评论
不是每一代70都能打上一代ti吗,970,780ti;1070.980ti
评论
没觉得有多大帮助。
第一,4x4 matrix MAD是极其针对DL需求搞出来的,用这玩意可以加速低精度需求的大矩阵相乘。但图形shader里大多数操作并不能map成这形式。即使某些特殊情况能用到,考虑到其所占的比例,额外添加这么多独立的Tensor Core也很不划算。
第二,当涉及到消费级图形领域时,你这种很特别的硬件功能也很难得到广泛应用,现有的着色语言没有支持这种操作,所以要想用还得嵌CUDA或者搞hack,最后收效还不好,开发者也不愿意用,何苦呢?
评论
主要是9系10系的频率和BOOST进步非常大,我是感觉下一代70在1080TI水平偏下一些,而80则是TTXp偏上一些,
评论
所以我觉得参考开普勒的泰坦和780TI的差别,GV102的泰坦给tensor core,1180TI砍掉,就行了。GV104完全不需要这个
评论
当初展示图里是没有帕斯卡这一代的,boost很高完全是是吃了制程的红利,而架构上的变化却不大而,volta在制程上不会变化太大,但是架构上会有较大改变,应该还是会有很大提升的,X70战1080ti应该也不是太大的问题
评论
这个倒是个很好的方法,顺便把泰坦的价格再提升一点。
我不太看好titan有tensor
除了第一代,titan的任何功能基本都是衍生于图形功能的。
但如果tensor真的受欢迎,老黄应该会单独来一个重tensor的产品线。类似FPGA。
毕竟GV100太大了,功能太全,成本太高
评论
那个150w FHHL不就是用来摊GV100成本的么
评论
这个大饼,不卖个5k美刀不能算摊成本吧
评论
…你从哪看出来我们在说的40%和Tensor那啥玩意有关系了
那是纯的浮点和功耗根本没人去管什么张量唉
评论
隐约记得当年AMD刚在小核心上尝到能耗比甜头的时候,有人在CHH上发帖说他看见大核心就恶心,现在我特想采访一下他
评论
480那功耗性能比烂到煎鸡蛋就别洗了吧
评论
关了两组sm的 完整版是5384
评论
那不是等于在说废话吗…最重要的东西不关心还关心什么…至于浮点计算的性能、能效这样的方面,肯定的啊,单单把大量的FP64单元砍掉其他都还不说,面积就已经回到600平方毫米的水平了,顶多再砍一点sm,频率可能再提功耗很宽裕,新Titan数据不就差不多了,如果只关心这些那猜都能猜到…
评论
老吴你不正义,一语双关!
评论
我理解错了,我以为5120是单精和双精总共5120个,所以我说÷3除不开。现在知道了5120只是单精
评论
你看的懂我的话吗? 我的回复,到底洗了什么?
480的性能,不仅战胜了当代的5870, 而且还领先AMD接下来一代的旗舰6970.
对于功耗我说了。 480和Fermi这一代的确是个问题,但这个问题就这么一代就结束了。
评论
480赢6970?哈哈哈哈
480连570都赢不了怎么赢6970 480也就比5870强个百分之10左右 然后功耗高的我都不想说了 史上第一块显卡为了散热把散热都外露了
评论
你自己翻翻当时6970发布的帖子吧?
一开始网友预期很高(论坛很high),但实际发布性能不及480,而且还有散热器打磨门。
不要把6970发布2-3年以后的性能,再拿来说事。 我说的性能就是当时发布那个时间点的性能。
评论
你自己去搜下tpu的测试吧 懒得跟你扯
评论
480对6970没赢,但也是半斤八两。
翻一下TPU的测评:
6970发布时GTX480 v.s. HD6970全分辨率平均成绩是100%:100%。
到GTX680发布时,GTX480 v.s. HD6970全分辨率平均成绩是73%:70%。相当于480领先了4%。你也许觉得全分辨率里面包含了一些过低的分辨率,不公平。
那么看在当时属于比较高的1920x1200分辨率:
6970发布时GTX480 v.s. HD6970全分辨率平均成绩是98%:100%。480稍弱
到GTX680发布时,GTX480 v.s. HD6970全分辨率平均成绩是70%:68%,480稍强。
与Kepler vs GCN相反,当年Fermi vs VLIW4/5其实是N卡战未来。
至于你那高到不想说的功耗,其实你也可以纵向查查,那功耗放到今天也算不上多夸张。
TPU数据:
GTX480 Average 223W, Peak 257W。
后来的苏厂火炉R9 290X Average 236W,Peak 271W。
Fury X Average 246W,Peak 280W。
现在当红的1080Ti Average 231W,Peak 267W。
讲道理,说起能耗比,RX480与1080的差距比当年GTX480与5870的差距还大。
好了,我提供了很多邪恶的弹药,你们继续吵吧。
评论
而且讲道理,6970也是个火炉来着。。。
评论
NV做啥都恶心,因为是绿色的啊,原谅卡
评论
确实有道理。
评论
还是女神的数据严谨,拜倒在你的石榴裙下
评论
其实SM框架没你说的那么大差别
GP104.png (505.72 KB, 下载次数: 0)
GP100.png (95.58 KB, 下载次数: 0)
评论
很对
看看GF100与GP100的SM··
GF110-SM.jpg (137.23 KB, 下载次数: 0)
GP100详细.png (615.57 KB, 下载次数: 0)
殊途同归··只是FP32变成了FP16+FP16
GV100进一步加入Tensor专用核心···更加细化SM内分组
评论
6970打不过570的,只能和480平手,而且570经过几轮更新把6970越甩越远
还有那能耗比,其实那个时候谈功耗用的是TPU最后一项,没错,就是烤机功耗,费米的拷机功耗不用说吧,特别难看
可是自从680出来以后,烤机功耗不能谈了,为神马,因为正义党不乐意了,开普勒拷机优化的比较好(哦,按他们的说法是作弊),相反7970的拷机变得难看,还有那7870,GCN1.0里只要是默频超过1000MHZ基本上全会死在烤机功耗上,而TPU的倒数第二项典型游戏功耗则表现良好,所以,从那以后,对比功耗以及能耗比要用倒数第二项而不是最后一项
偶们再回过头来看看费米,它的倒数第二项如宽妹所说,GTX4XX是比较高,但并非太离谱,而到了GTX5XX,能耗比则到了一个比较正常的水平,那个时候TPU计算能耗比用的就是倒数第二项,偶们可以看到,在TPU的能耗比数据里,GTX580的能耗比比HD6970甚至要强一点点,但是却从不见一个人提起过,因为那个时候只准谈烤机功耗,还要破解之后再谈,否则后果乃懂的
评论
Tensor单元本质就是经过优化int8整数计算单元,按照NV的架构设计,每个SM里以前主要是FP32计算单元,GP10x里增加FP16和FP64单元,GV10x里增加的int8计算单元。对于AI这种逻辑计算,浮点是大材小用,只需要整数计算单元即可,而整数计算所需的晶体管要比浮点少得多
电路 电子 维修 我现在把定影部分拆出来了。想换下滚,因为卡纸。但是我发现灯管挡住了。拆不了。不会拆。论坛里的高手拆解过吗? 评论 认真看,认真瞧。果然有收 电路 电子 维修 求创维42c08RD电路图 评论 电视的图纸很少见 评论 电视的图纸很少见 评论 创维的图纸你要说 版号,不然无能为力 评论 板号5800-p42ALM-0050 168P-P42CLM-01
·中文新闻 阿曼达·斯蒂尔(Amanda Platell):哦,迈琳(Myleene),我对你的
·中文新闻 迪拜的秘密性交易 - 和加油的英国男人 - 暴露了:在一次特别调